4.6. Payload关键字¶
Payload关键字检查数据包或流的有效载荷的内容。
4.6.1. content¶
content关键字在规则中非常重要,您可以在引号之间写下您希望规则匹配的content。 最简单的content格式是:
content: ”............”;
在一条规则中使用多个content是有可能的。
content基于字节进行匹配。一个字节有256个不同的值(0-255)。你可以匹配所有字符; 从a到z,大写和小写以及所有特殊标记。但并非所有字节都是可打印字符。对于这些字节,可以使用十六进制来表示,许多编程语言使用0x00表示法,这里0x表示它涉及二进制值,但是规则语言使用 |00| 表示法。 这种表示法也可用于可打印字符。
例如:
|61| 表示 a
|61 61| 表示 aa
|41| 表示 A
|21| 表示 !
|0D| 表示 回车符
|0A| 表示 换行符
有些字符不允许在content中使用,因此这些字符是规则定义表示符,要匹配这些字符,你必须使用十六进制表示法。这些字符包括:
“ |22|
; |3B|
: |3A|
| |7C|
用大写字符来书写16进制符号是一种惯例。
例如,你要在规则的content中写 http:// , 应当这样写: content: “http|3A|//”; 如果你在规则中使用16进制, 一定要这些字符放在管道符之间。否则16进制的内容会被当作content普通文本的一部分。
一些例子:
content:“a|0D|bc”;
content:”|61 0D 62 63|";
content:”a|0D|b|63|”;
规则可以定义检查整个载荷与content匹配,或者仅检查载荷的特定部分,晚点我们会讨论这个问题。 如果你没有在规则中定义特殊的选项,那么将在整个载荷中进行匹配。
默认情况下,模式匹配区分大小写。content定义必须准确,否则不会匹配。

图例:
同样,可以使用 ! 来表示content内容取反(例外情况)匹配。
例如:
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"Outdated Firefox on
Windows"; content:"User-Agent|3A| Mozilla/5.0 |28|Windows|3B| ";
content:"Firefox/3."; distance:0; content:!"Firefox/3.6.13";
distance:-10; sid:9000000; rev:1;)
如 content:!”Firefox/3.6.13”;, 这意味着使用的Firefox版本不是3.6.13的时候,会产生一条报警。
注解
在content中,下列字符必须进行转义:
; \ "
4.6.2. nocase¶
如果您不想区分大小写字符,可以使用nocase。nocase关键字是content修饰符。
这个关键字的格式是:
nocase;
你必须把它放在你想修饰的content后面, 像这样:
content: “abc”; nocase;
nocase例子:

它对规则中的其他内容没有影响。
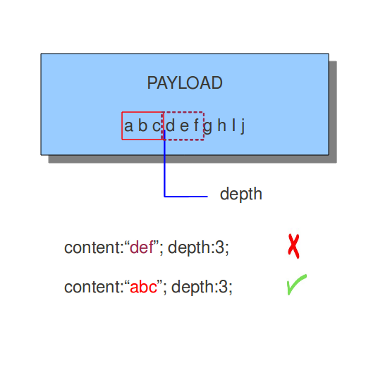
4.6.3. depth¶
depth关键字是一个绝对content修饰符,他跟在content后面。depth作为content修饰符必须要跟一个数字, 如:
depth:12;
depth后的数字表示将检查载荷从开头到多少字节的内容。
如:
4.6.4. startswith¶
startswith关键字类似于depth. 它没有任何参数并且必须跟在一个content关键字后面。它表示content将从一个缓冲区的开头进行匹配。
如:
content:"GET|20|"; startswith;
startswith 相当于下面规则的简写:
content:"GET|20|"; depth:4; offset:0;
对于同一个content定义, startswith 不能和 depth, offset, within 或 distance 写在一起。
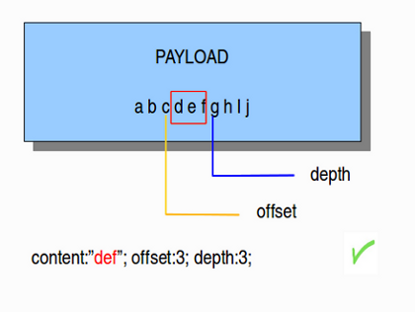
4.6.5. offset¶
关键字指定从载荷中的哪个字节开始查找匹配。例如offset:3; 从第四个字节开始查找匹配。

offset和depth关键字可以并且经常组合在一起使用。
例如:
content:“def”; offset:3; depth:3;
如果在规则中使用图中组合,那么将检查载荷中的第四到第六个字节。
4.6.6. distance¶
distance关键字是相对content修饰符。意思是它表示当前content关键字与前一个content之间的关系。跟在前一个匹配后面,Distance有它的作用。distance关键字必须要跟一个数字。你指定的distance数值, 决定了载荷中从上一个匹配到当前匹配之间的字节数。Distance仅仅指定Suricata从哪里开始查找匹配。因此, distance:5; 表示可以在上一个匹配后面5字节的任何地方进行匹配。为了限制Suricata匹配载荷中的最后字节,使用 ‘within’ 关键字。
distance的例子:

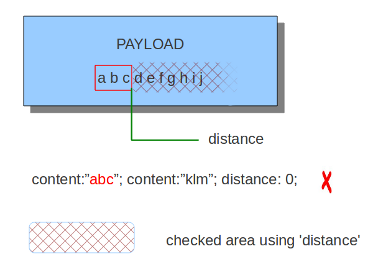

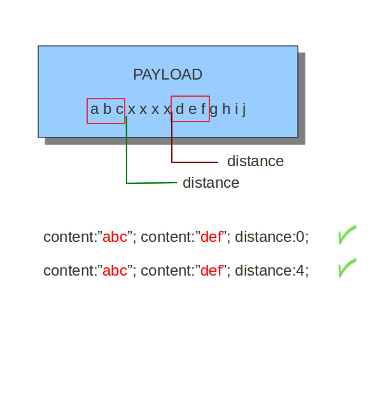
Distance也可以是一个负值。这用来检测多个匹配之间部分相同的内容(参考例子)或者是完全在前一匹配之前的内容。但是这并不经常使用,因为有可能使用其它关键字来达到相同的目的。

4.6.7. within¶
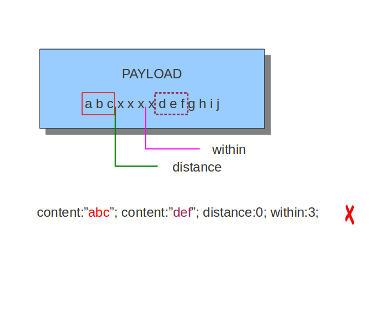
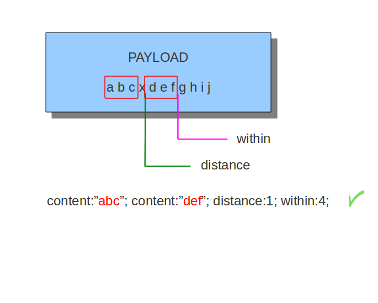
within关键字是相对于前一个匹配而言的,它必须跟一个数字。使用within关键字需要确认的是,在载荷的前一个匹配到within设定的字节之间只有一个匹配。within不能设置为0。
如:

使用within进行匹配的例子:

第二部分内容(整体)必须距离第一部分内容3个字节以内。
如前所述,distance和within可以在规则中很好地组合在一起。如果你希望Suricata检查载荷中某个特定的部分,使用within.
4.6.8. isdataat¶
isdataat关键字的目的是检查载荷的特定部分是否存在数据。这个关键字以一个数字(表示位置)开始,然后可能跟上一个’relative’,以逗号与前面的数字分隔。这里的’relative’表示距离前一个匹配指定字节的位置是否存在数据。
你可以像下面两个例子这样使用:
isdataat:512;
isdataat:50, relative;
第一个例子表示将检查载荷的第512个字节是否存在数据,第二个例子表示载荷中上一个匹配后的第50个字节是否存在数据。
你可以在isdataat前面使用 (!) 来表示不存在数据则匹配。

4.6.9. dsize¶
你可以使用dsize关键字来检查整个载荷的长度,如可以检查载荷异常的长度。这在检测缓冲区溢出时会非常有用。
格式:
dsize:<number>;
规则中使用dsize的例子:
4.6.10. rpc¶
rpc关键字可用来在SUNRPC CALL中匹配RPC过程编号和RPC版本。
您可以使用通配符表示匹配模式,使用*通配符可以匹配所有版本和/或过程编号。
RPC(远程过程调用)是一种允许计算机程序在另一台计算机(或地址空间)上执行过程的应用程序,它用于进程间通信。参见 http://en.wikipedia.org/wiki/Inter-process_communication
格式:
rpc:<application number>, [<version number>|*], [<procedure number>|*]>;
规则中使用rpc关键字的例子:
4.6.11. replace¶
replace作为content修饰符只能在ips中使用,它会改变网络流量,会将后面的内容从 (‘abc’) 替换成(‘def’)。如:

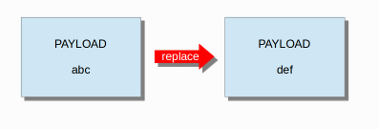
replace修饰符必须包含与其替换的内容一样多的字符,它只能用于单个数据包,不能在 标准化缓冲区 如HTTP uri中使用或重组流中进行匹配。
在使用replace关键字后,Suricata会重新计算校验和并更改。
4.6.12. pcre (兼容Perl的正则表达式)¶
关键字pcre使用正则表达式进行特定匹配。有关正则表达式的更多信息,请访问此处 http://en.wikipedia.org/wiki/Regular_expression.
pcre复杂度高,并且对性能影响大。因此,为了避免Suricata经常进行pcre正则匹配,pcre大多与 ‘content’一起使用。在这种情况下,必须要先匹配content,再进行pcre检查(正则匹配)。
pcre的格式:
pcre:"/<regex>/opts";
pcre的例子。在此示例中,如果载荷中包含六个数字,则将匹配:
pcre:"/[0-9]{6}/";
规则中使用pcre的例子:
有一些pcre的特性可以修改:
- pcre默认是大小写敏感的.
- .(点)是正则表达式的一部分,它匹配除换行符之外的每个字节.
- 默认情况下,载荷将被当作一行来检查.
可以使用以下字符修改这些特性:
i pcre大小写不敏感
s pcre会检查换行符
m 可以使一行(载荷)计为两行
这些选项是perl兼容修饰符。要使用这些修饰符,您应该将它们添加到正则表达式后面。像这样:
pcre: “/<regex>/i”;
Pcre兼容修饰符
还有一些pcre兼容的修饰符可以改变它的特性,它们是:
A: 模式必须从缓冲区的开头匹配. (在pcre中 ^ 跟这里的 A 类似.)E: 忽略缓冲区/载荷末尾的换行符.G: 切换贪婪模式匹配.
注解
必须在内容中转义以下字符:
; \ "
4.6.12.1. Suricata的修饰符¶
Suricata有自己特定的pcre修饰符。它们是:
R: 相对于前一个模式匹配的匹配。类似于distance:0;U: 使用pcre匹配规范化的uri。它匹配uri_buffer就像uricontent和content组合http_uri.U一样,可以和/R一起组合使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-uri缓冲区内,更多信息请参考 HTTP URI Normalization.




I: 在HTTP-raw-uri上进行pcre匹配,在http_raw_uri的同一个缓冲区上进行匹配,可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-raw-uri缓冲区内,更多信息请参考 HTTP URI Normalization.P: 在HTTP-request-body上进行pcre匹配,在http_client_body的同一个缓冲区上进行匹配, P 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-request-body内.Q: 在HTTP-response-body上进行pcre匹配,在http_server_body的同一个缓冲区上进行匹配, Q 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-response-body内.H: 在HTTP-header上进行pcre匹配, Q 可以和/R一起使用。注意 H 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-response-header内.D: 在非标准化的头部上进行匹配,在http_raw_header的同一个缓冲区上进行匹配, D 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-raw-header内。M: 在request-method上进行匹配,在http_method的同一个缓冲区上进行匹配, M 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-method内。C: 在HTTP-cookie上进行匹配,在http_cookie的同一个缓冲区上进行匹配, C 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-cookie内。S: 在HTTP-stat-code上进行匹配,在http_stat_code的同一个缓冲区上进行匹配, S 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-stat-code内。Y: 在HTTP-stat-msg上进行匹配,在http_stat_msg的同一个缓冲区上进行匹配, Y 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-stat-msg内。B: You can encounter B in signatures but this is just for compatibility. So, Suricata does not use B but supports it so it does not cause errors.您可能在规则中遇到B,但这只是为了兼容性。 因此,Suricata不使用B但支持它,这样不会导致错误。O: 覆盖pcre匹配限制的配置。V: 在HTTP-User-Agent上进行匹配,在http_user_agent的同一个缓冲区上进行匹配, V 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-User-Agent内。W: 在HTTP-Host上进行匹配,在http_host的同一个缓冲区上进行匹配, W 可以和/R一起使用。注意 R 是相对于上一个匹配而言的,所以两个匹配都必须在HTTP-Host内。